1概述
Apache Flink是一个分布式计算引擎,用于在无边界和有边界数据流上进行有状态的计算。它能够在所有常见的集群环境中运行,且能够以内存速度和任意规模进行计算。
1.1无界流与有界流
- 无界流:有定义流的开始,但没有定义流的结束,数据会无休止地产生。比如采集MySQL Binlog数据和读取MQ中的数据。
持续/实时处理 - 有界流:既有定义流的开始,也有定义流的结束。比如读取RDB中表数据和读取HDFS上的文件。
批/离线处理
1.2有状态计算
- 状态
state(一个变量)是流处理特有的。由于流处理一般要进行增量计算——数据逐条处理,每次计算都是建立在上一次计算结果之上的,而Flink本身就能够提供状态管理以支撑增量计算。
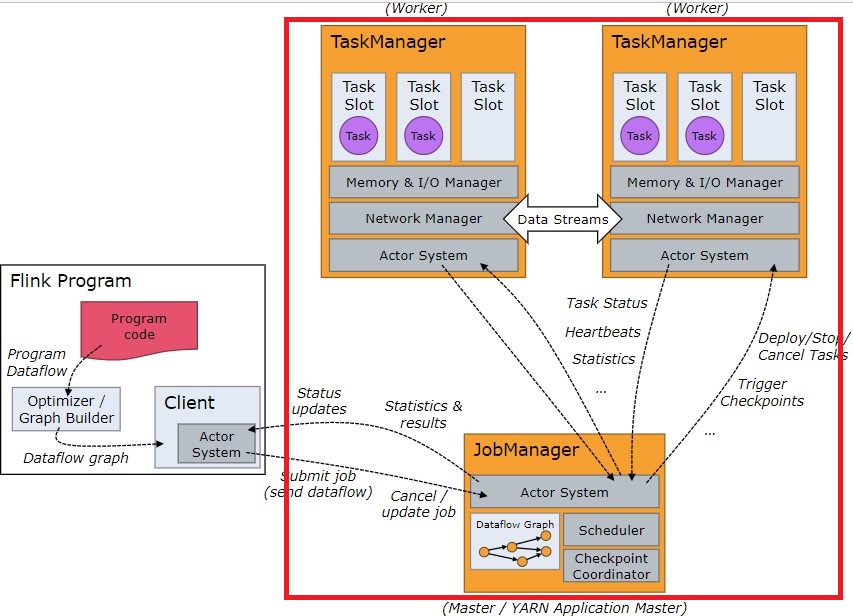
2架构
Flink Runtime采用了标准的主从架构
2.1JobManager
Dispatcher:向客户端提供了REST接口,用以提交作业。并将提交的作业传递给一个新的JobMaster。JobMaster:管理一个作业的执行。在Flink中可以存在多个。ResourceManager:负责Flink中资源的分配与回收(比如:task slot),在Flink中只能存在一个。
2.2TaskManager
一个Flink Job中包含多个task。任务管理器负责执行作业流中的task任务,且在Flink中必须至少有一个TaskManager(JVM进程)。
task slot:资源调度的基本单位。一个槽位可以执行一个task。state backend:状态管理。
1 | 1. MemoryStateBackend(默认配置)——内存操作:状态`state`在TaskManager内存中维护,checkpoint快照存储在JobManager内存中。强调高性能,适用于本地开发和调试。 |
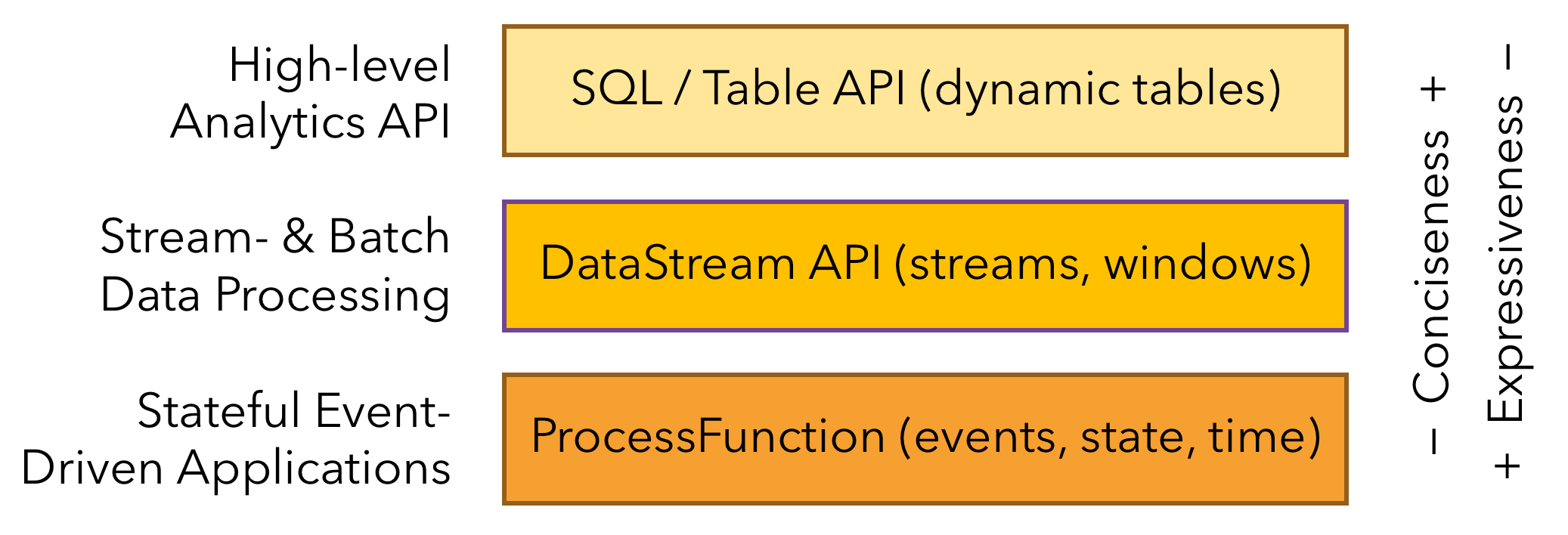
3分层API
要使用Flink进行流处理,前提是能够开发出可以在Flink上运行的应用程序,这就需要API接口作为支持。
Flink根据抽象程度分层,提供了三种不同的API。每一层级API在简洁性和表达力上有着不同的侧重。
3.1ProcessFunction
用户可以在此抽象层中对状态和时间进行细粒度控制(比如:任意地修改状态数据、注册定时器来触发回调操作等),允许程序实现复杂的计算。
大多数应用程序不需要使用上述最底层的抽象API。
3.2DataStream API/DataSet API
DataStream API:应用于实时的流处理。DataSet API:应用于离线的批处理。
所写程序未经过优化器优化。
3.3SQL/Table API
Flink支持两种关系型的API:Table API和SQL。它们集成在一个抽象层,构成批流统一的API。
- 为了在流上使用SQL查询,数据流会记录到Table表(输入流<—>Source Table,Sink Table<—>输出流)
- 在Table表上进行查询,将产生一个新的动态表(编程角度:SQL支持链式调用)
SQL/Table API统一了DataStream API和DataSet API,一般情况下,建议使用该层API开发应用程序。
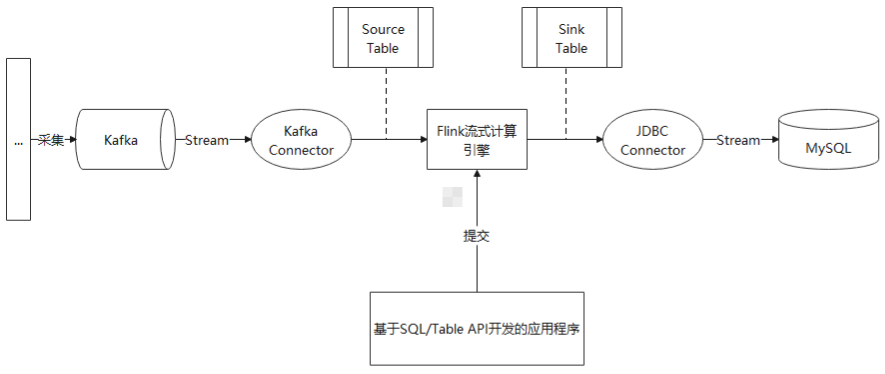
4连接器(SQL/Table API Connector)
上述接口仅仅提供了应用程序与Flink的交互,而Flink作为一个流计算引擎,必然需要与第三方/外部系统交互数据,交互的工具就是Connector连接器。Flink目前支持的连接器有:Kafka、JDBC、Elasticsearch等。
Flink默认是没有打包Connector的,所以在程序开发之前,我们需要下载各个Connector所依赖的Jar包。
4.1 Kafka Connector使用示例
Flink提供了一套与表连接器(table connector)一起使用的表格式,定义了数据和表结构的映射关系,支持JSON、CSV等类型。
1 | -- 以下示例展示了如何创建连接Kafka数据的表,同时指定了数据映射格式 |
4.2小结
下图描述了一个流处理场景:源源不断的数据流向Kafka。应用程序会从Kafka获取数据源,经过Flink转换处理,最终持久化到MySQL中。
5PyFlink
PyFlink即Flink on Python,旨在将Flink生态系统的全部功能输出给Python用户
5.1环境安装
- Python版本要求:3.6+
- 安装命令:pip install apache-flink==1.10.0
5.2TableEnvironment
1 | # TableEnvironment是SQL/Table API编程的核心,我们总是使用它创建source/sink table表、处理SQL查询、执行Job作业等 |
- 流处理的编程主体结构
1 | # 1. 导入相关包 |
- PyFlink1.10版使用文档
https://ci.apache.org/projects/flink/flink-docs-release-1.10/api/python/index.html
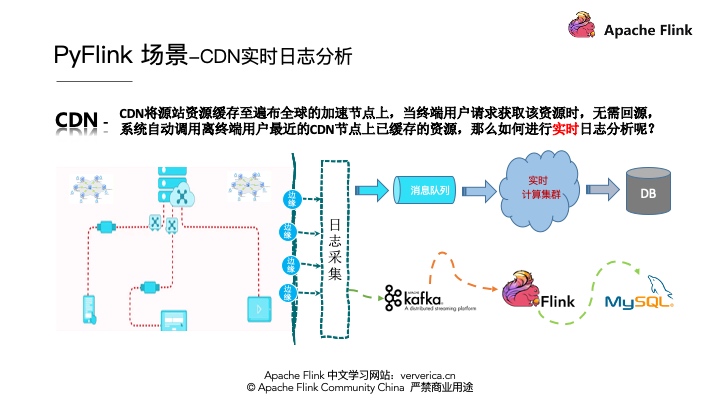
6某CDN日志实时分析案例
6.1架构
CDN日志的解析一般有一个通用的架构模式,就是首先要将各个边缘节点的日志数据进行采集,一般会采集到消息队列,然后将消息队列和实时计算集群进行集成进行实时的日志分析,最后将分析的结果写到存储系统里面。将架构实例化,消息队列采用Kafka,实时计算采用Flink,最终将数据存储到MySQL中。如下图所示:
1 | # CDN 假数据 "uuid,client_ip,request_time,response_size,uri" |
本案例将从CDN访问日志中,获取如下统计指标:
- 按IP统计资源访问量
- 按IP统计资源下载总数
- 按IP统计资源平均下载速度
6.2Kafka数据读取DDL定义
| 字段名 | 类型 | 描述 |
|---|---|---|
| uuid | VARCHAR | 日志的标识符 |
| client_ip | VARCHAR | 请求CDN资源的客户端IP |
| request_time | BIGINT | 处理请求花费的时间 |
| response_size | BIGINT | 返回的资源体量 |
| uri | VARCHAR | 请求的网址 |
1 | kafka_source_ddl = """ |
6.3MySQL数据写入DDL定义
| 字段名 | 类型 | 描述 |
|---|---|---|
| client_ip | VARCHAR(255) PRIMARY KEY | 请求CDN资源的客户端IP |
| access_count | BIGINT | 当前的访问量 |
| total_download | BIGINT | 下载总量 |
| download_speed | DOUBLE | 下载速度 |
1 | mysql_sink_ddl = """ |
6.4核心统计逻辑
在核心统计逻辑定义好之后开始执行作业:
1 | # t_env为TableEnvironment实例对象 |
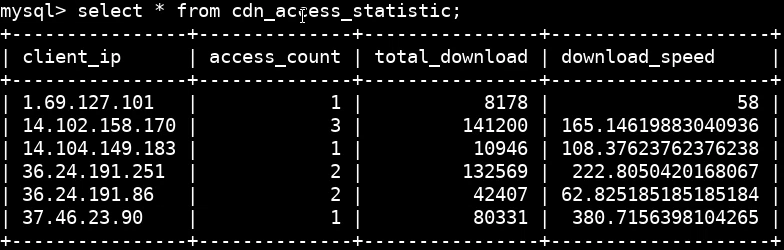
统计情况示例:
6.6环境配置
- MySQL库表创建
1 | CREATE DATABASE flink DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; |
- Kafka主题创建
1 | ./bin/kafka-topics.sh --create --replication-factor 1 --partitions 1 --topic cdn_access_log --zookeeper localhost:2181 |
- Connector的Jar包下载
1 | cd $PYFLINK_LIB |
1 | $PYFLINK_LIB/../bin/flink run -m localhost:4000 -pyfs cdn_connector_ddl.py -py cdn_demo.py |